Eccoci finalmente giunti alla tanto attesa lezione sui database.
Introduzione ai database relazionali
Un database è una raccolta organizzata di informazioni. Pensiamo al mitico album Panini: quale migliore esempio per illustrare il concetto di base dati!
Ogni squadra due pagine (ormai sono diventate quattro!), per ciascun giocatore fotografia e scheda personale.
In informatica, all’inizio, i database erano davvero simili all’album Panini: semplici file di testo dai quali attingere informazioni spesso disordinate. Era necessario scrivere programmi che stabilissero un separatore di risultati (è il caso del formato “comma separeted value” che potete ottenere salvando un foglio excel con estensione .csv).
Vennero poi i database, file strutturati e capaci di estrarre informazioni ordinate. Esistono diversi tipi di database, è possibile però eseguire interrogazioni su tutti con un linguaggio (quasi) standard: SQL.
I database relazionali rappresentano l’ultima generazione di raccolta dati. Pensiamo di gestire l’elenco di tutti i calciatori del nostro campionato, con presenze e gol divisi squadra per squadra.
Prima dei db relazionali avremmo avuto un’unica, grande, tabella di questo tipo:
- nome_giocatore;
- anno_nascita;
- ruolo;
- squadra;
- anno;
- presenze;
- gol.
Un approccio del genere è problematico per diversi motivi. Innanzitutto, la ridondanza delle informazioni. Pensate il caso di Franco Causio, ad esempio: avrà giocato quasi 25 anni (!), in 9 squadre diverse.
Ci troveremmo a scrivere 25 volte lo stesso nome-cognome, la stessa data di nascita, lo stesso ruolo, e parecchie volte la stessa squadra (11 anni la Juventus).
Un inutile spreco di byte, nonché una “sconfitta” logica: perché obbligare il computer a ricordare delle informazioni uguali?
Ipotizziamo poi di trovare dati da cambiare. In questo esempio non è possibile, ma in altri ambiti può accadere di dover aggiornare dei dati.
Anzi… anche in questo caso ci saremmo trovati a cambiare delle statistiche: pensate al caso di Luciano, il calciatore del Chievo che un bel giorno ci fece la sorpresa di chiamarsi invece Eriberto, e di essere nato perfino in altra data!
Con una megatabella strutturata nel modo precedente, avremmo dovuto ricercare a manina tutti i dati di tal Eriberto e, sempre a manina, cambiare il nome in Luciano!
Oltretutto, va bene che i computer moderni sono dei mostri se paragonati a quelli di anni fa, ma i tempi richiesti per scorrere una tabella nella ricerca di informazioni possono comunque essere elevati.
Pensate in una pagina web, dove i tempi di risposta sono già compromessi di loro a causa della lentezza della linea telefonica, cosa significherebbe aggiungere qualche secondo in più in attesa di una risposta da un’interrogazione ad un database.
I database relazionali rappresentarono una svolta nell’informatica. La tabella precedente sarebbe stata strutturata in questo modo:
- tabella giocatori:
id_giocatore
nome_giocatore
anno_nascita
ruolo - tabella squadre:
id_squadra
nome_squadra - tabella squadre_giocatori:
id_giocatore
id_squadra
anno
presenze
gol
Come vedete, è stato possibile scorporare i dati in 3 tabelle, due (giocatori e squadre) per raggruppare dati ridondanti e una (squadre_calciatori) per le informazioni univoche. In un database relazionale non dovrebbero esistere ripetizioni. Ecco perché abbiamo raggruppato anche le squadre in una tabella a sé.
Avrete già notato che per le due tabelle contenente informazioni univoche (giocatori e squadre), abbiamo anche inserito un nuovo campo: id, ovvero l’identificatore (o campo chiave).
E’ un campo numerico grazie al quale potremo mettere in relazione (parliamo di db relazionali) i campi comuni a più tabelle.
Passiamo ad un esempio pratico per chiarire meglio il concetto: vediamo come potrebbe essere strutturato un database con i dati di carriera di Franco Causio, sia in un approccio “vecchia maniera”, sia in un db relazionale.
Prendo come base l’Almanacco Panini 1987 (quindi dati aggiornati fino al 1985-86 incluso).
Approccio “vecchia maniera”
tabella calciatori (unica tabella della base dati)
|
Se qualcuno di voi non ha ancora capito la differenza tra un database relazionale ed uno tradizionale, bhè provi a ricopiare la tabella qui sopra (non un “CTRL-C/CTRL-V”) ma un “copia a manina”) e capirà cosa vuol dire scrivere più di 20 volte la stessa cosa grrrr
Prendiamo invece la stessa situazione, gestita con un db relazionale:
tabella giocatori:
|
tabella squadre:
|
||||||||||||||||||||||||||||
tabella squadre_giocatori:
|
Guardate bene l’ultima tabella: al posto del nome del giocatore e dei suoi dati anagrafici, ripetiamo soltanto il campo ID (in questo caso, 1).
Con delle particolari istruzioni SQL (che vedremo in seguito) è possibile mettere in relazione le tre tabelle ed estrarre dati esattamente come avevamo fatto “a manina” nel primo esempio di oggi.
Al posto di “Franco Causio” possiamo scrivere, ogni volta, il suo campo ID, con un notevole risparmio di codice ed efficienza.
Pensate in una tabella contenente migliaia di calciatori cosa significherebbe cercare “Franco Causio”: il motore del database dovrebbe confrontare tutte le stringhe, con un notevole ritardo delle prestazioni. Con un indice numerico diventa tutto più veloce.
Andiamo adesso a chiarire termini tecnici di un database:
- Record
Un record è l’insieme delle informazioni di un elemento. Semplificando il discorso, un record è una riga di una tabella. Nel nostro caso, la tabella “squadre_giocatori” contiene 22 record. - Campo
Un campo è una caratteristica della tabella. Semplificando, è il nome della colonna. Nell’ultimo esempio qui sopra, “id_giocatore”,”id_squadra”, “presenze” ecc. sono i campi della tabella “squadre_giocatori”. - SQL
Structured Query Language. E’ un linguaggio utilizzato per interrogare diversi tipi di database. Tra un db ed un altro, la sintassi subisce poche variazioni ed è quindi semplice accedere a diverse raccolte di dati. - Query
E’ un’interrogazione al database. Attraverso il linguaggio SQL, con una query è possibile estrarre informazioni e manipolare i dati.
Esempi di query:
- query di interrogazione: “select anno_nascita from giocatori where nome=’Franco Causio'”
- query di cancellazione: “delete from giocatori where nome=’Franco Causio'”
Il modo in cui, praticamente, i comandi vengono inviati ad una base dati cambia a seconda del db utilizzato.
Con Microsoft Access è possibile costruire le query in visuale ed inviarle direttamente dal programma (è un db particolare, che in un solo file contiene tool, motore, strumenti di sviluppo).
Con mysql è possibile utilizzare la riga di comando (anche da DOS, se è installato mysql su win – SHELL se installato su Mac o Linux), tool particolari o script php. Una pagina PHP consente un accesso diretto a qualsiasi db mysql (di cui si conoscano username e password ovviamente.)
Utilizzare mysql da riga di comando
Passiamo adesso alla parte pratica di questa lezione. Di sicuro la maggior parte di voi avrà utilizzato Microsoft Access. Si tratta di un database particolare, come chiarivamo prima.
Access contiene infatti, in un unico file, sia il motore che interpreterà le query, sia il front-end grafico (le tabelle viste già come se fossero un foglio Excel, righe-colonne), sia il tool di interrogazione (vi consente di creare query in visuale..), sia il tool di sviluppo (editor Visual Basic).
Forse è meglio che, per un po’, facciate finta di non aver mai conosciuto Access. Potrebbe confondervi le idee, in quanto si tratta di una base dati pensata per un uso Home o per il piccolo ufficio.
Su internet è difficile utilizzare Access (anche se c’è chi lo fa, e con un po’ di esperienza anche con discrete prestazioni) perché non è un database pensato per connessioni multiple.
In questo corso utilizzeremo MySql. Il motivo è semplice: si tratta di un database gratuito e utilizzato il più delle volte in applicazioni internet PHP. Si tratta di due progetti open-source, il connubio era inevitabile.
Attenzione però: nulla vi vieta di utilizzare PHP anche con altri database (perfino con Access..), cosi come nulla vi vieta di scrivere applicazioni in altri linguaggi (come Java) con supporto al database MySql.
Su internet comunque troverete quasi sempre applicazioni scritte per PHP-MySql. Le prestazioni di questo database sono eccellenti, e può essere utilizzato anche per progetti di grande dimensioni.
Ho gestito tabelle con oltre 100mila record e con tempi di risposta nell’ordine dei centesimi di secondo.
Il problema è però il supporto online. Se avete installato EasyPHP/XAMPP, avete già il motore MySql in ascolto sul vostro computer. Potete creare (poi vedremo come) più database, secondo le vostre esigenze. Su internet non è cosi.
Che io sappia, è quasi impossibile trovare hosting gratuito che offra database MySql (Altervista ha il famoso discorso dei crediti, ma è arduo raggiungerli).
Quindi, se avete bisogno di un database (necessario se volete gestire una community: login utenti, forum, guestbook), dovete preventivare anche la spesa di un provider a pagamento. Se invece volete “solo” imparare ad utilizzare MySql, potete fare le vostre prove in locale senza problemi, grazie ad EasyPHP/XAMPP.
Potete anche decidere di scaricare il pacchetto MySql dal sito ufficiale, mysql.org, ma la configurazione non è semplicissima (e se già avete installato EasyPHP/XAMPP, vi sconsiglio di aggiungere altro).
Se venite dal mondo Access, forse pensate a MySql come un tool da aprire da qualche parte con un doppio click.
Non è cosi. MySql è un “motore” in ascolto su una porta del computer. E’ possibile inviare istruzioni in linguaggio SQL attraverso la riga di comando. Possiamo anche utilizzare dei tool grafici, ed è questo che faremo in seguito, tuttavia per ora useremo la riga di comando.
Le operazioni che faremo da adesso in poi possono essere eseguite indifferentemente da una pagina PHP, dalla riga di comando o da un tool. Userà volta per volta un metodo diverso cosi da illustrarli tutti, comunque voi potete usare quello che volete.
Partiamo con la creazione di un database, e per questo utilizzeremo la riga di comando.
Per prima cosa dobbiamo avviare il motore MySql. Non occorre lanciare EasyPHP/XAMPP (per ora non dobbiamo scrivere codice PHP), basta avviare Mysqld (tecnicamente, il “demone” MySql).
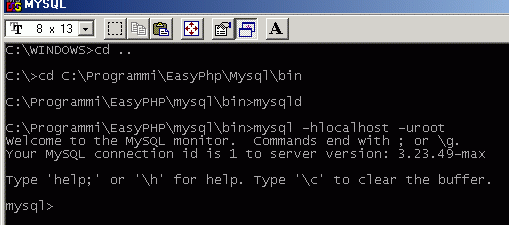
Apriamo il prompt Dos/Shell e portiamoci nella cartella Mysql, lanciando il programma. I file eseguibili sono ovviamente nella cartella “bin”, classica disposizione ambienti UNIX.
Lanciamo il programma digitando dal prompt dei comandi: mysqld
Una volta lanciato il demone dobbiamo digitare questa riga per averne il controllo:
mysql -hlocalhost -uroot
Non è una formula magica:
- “mysql” è il nome del programma da lanciare (dentro la cartella bin esistono altri eseguibili, come mysqldump che serve per i backup). Possiamo anche scrivere mysql.exe, va bene lo stesso.
- “-h” è un parametro: mysql cerca una connessione, ma ovviamente dobbiamo dirgli dove andare. Omettere questo parametro sarebbe come lanciare Internet Explorer e lasciare la pagina bianca.
- “localhost” è il valore del parametro “h”: l’host su cui connettersi. In questo caso, il locale del nostro computer, che abbiamo avviato prima con il comando mysqld.
Su internet, gli host vengono spesso identificati da un indirizzo del tipo “sql.nomesito.com”.
- “-u” è il parametro che precede l’username
- “root” è appunto l’username
In realtà l’username può cambiare, ma nelle installazioni di default è “root”, quindi credo che ciascuno di voi abbia ottenuto la connessione con successo. Se è cosi, avrete ricevuto un messaggio di benvenuto da Mysql.
Cosa abbiamo fatto? Riportiamo l’esempio nella vita di tutti i giorni. Immaginate una macchina.
Finché non accendete il quadro, potete anche giocare con il freno, con la frizione, con le luci… non accadrà nulla, è come se foste in presenza di un giocattolo (a meno che non siate in discesa e non proviate una partenza all’americana, ma non complichiamo le cose..).
Una volta acceso il motore (con l’apposita chiave, una diversa per ogni vettura) potete utilizzare i comandi.
Questo è quello che abbiamo fatto dal prompt DOS/Shell: portandoci nella cartella del programma Mysql e lanciando mysqld, abbiamo “acceso il motore”; con il programma “mysql” invece abbiamo modo di controllare ed interagire con esso.
Adesso che abbiamo “il cruscotto dei comandi”, cosa possiamo fare? Per prima cosa, creiamo un nuovo database. Quando creiamo un db con Access, questo coincide con un file. Con MySql non è propriamente cosi, si tratta di un db in ascolto su una porta ed i file (comunque presenti nella cartella “data”) sono particolari.
Per intenderci: con Access potete eseguire un backup del db semplicemente copiando/incollando il file, con MySql no.
Creiamo allora un database, chiamandolo “corso_php” (mi raccomando, evitate gli spazi tra i nomi e sostituiteli sempre con gli underscore). Il comando da digitare è:
create database corso_php; (notate l’assenza dei doppi apici per delimitare il nome del db)
Attenzione: in mysql ogni comando va seguito da un punto e virgola (“;”). Se omettete il carattere, troverete un segnale di richiesta comando (del tipo “=>”).
Digitate comunque il punto e virgola e l’istruzione verrà eseguita.
Verifichiamo se il database è stato creato con il comando show databases;
Nel mio pc, trovo questo output (gli altri database che vedete sono ovviamente stati creati in precedenza, voi dovreste trovare solo quello “corso_php”):
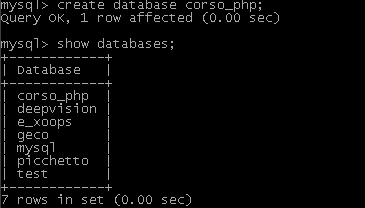
(adesso non andate a denunciarmi perché vedete un db chiamato “picchetto”, non è riferito al totonero, è solo un gioco che faccio con mio fratello ogni week-end: inserisco nel db 15 partite e dobbiamo indovinare i risultati, c’è poi anche il computer che estrae da solo il suo pronostico).
Una volta creato un database, dobbiamo dare a mysql l’ordine di utilizzarlo. In un host (anche nel nostro locale) possiamo avere più database (come nel mio caso). Va quindi specificato quale utilizzare con questo comando:
use corso_php;
Adesso che abbiamo a disposizione un database, possiamo popolarlo creando una tabella. La sintassi è:
CREATE TABLE nome_tabella (nome_campo tipo_campo opzioni_campo, nome_campo tipo_campo opzioni_campo ecc., CHIAVI E INDICI);
Sulla prima parte dell’istruzione (CREATE TABLE nome_tabella) credo non ci sia bisogno di commenti: diamo a mysql l’ordine di creare una nuova tabella con il nome passato come parametro. Anche qui, evitate caratteri strani (lettere accentate o spazi nel nome).
Tra parentesi, separati da virgola, dobbiamo inserire i nomi dei campi: quelli che, nell’esempio di prima, erano “id_giocatore”, “nome_giocatore”, “anno_nascita”, “ruolo”.
Dopo il nome del campo, dobbiamo specificare il tipo di dato. Un campo può infatti contenere una stringa (ad esempio, un nome), un numero, una data e perfino un valore binario (magari un’immagine).
Dopo il tipo di dato, se desiderate, vanno specificate le opzioni. Per ora utilizzeremo tre opzioni: unsigned (per i valori numerici che non permettono coefficenti negativi), not null (per campi obbligatori), auto_increment (per i contatori: automaticamente, inserendo un nuovo record, questo campo incrementa il suo valore di 1 unità).
Dopo aver elencato tutti i campi, possiamo utilizzare le opzioni di indicizzazione. Le opzioni di indicizzazione possono rendere un campo chiave primaria (il caso dell’ID di prima), ovvero valore univoco.
Se dichiariamo un campo chiave primaria, e poi cerchiamo di inserire due valori uguali per quel campo, riceviamo un errore. Infine, possiamo dichiare un campo come indice. Gli indici servono per velocizzare le ricerche nelle query.
Mentre ciascuna tabella può usare 1 sola chiave primaria, è possibile dichiarare più indici (sui campi dove conviene farlo, è un aspetto evoluto dei database che vedremo nelle lezioni successive: per ora limitatevi a dichiarare come indice la chiave primaria).
Solitamente, il campo chiave è sia indice che contatore. Se un campo è contatore, abbiamo anche la certezza di inserirvi un valore diverso per ogni record (visto che Mysql incrementerà da solo il valore), di riflesso avremo un campo univoco.
Chi ha dimestichezza con Access e crea tabelle in visualizzazione struttura, avrà familiari i concetti sopra descritti.
Andiamo a creare la prima tabella dell’esempio precedente: quella contenente nome-data nascita-ruolo dei calciatori. L’istruzione da inviare a mysql è questa:
CREATE TABLE giocatori (id_giocatore INT (11) UNSIGNED NOT NULL AUTO_INCREMENT, nome_giocatore VARCHAR (100), anno_nascita DATE, ruolo VARCHAR (1), PRIMARY KEY(id_giocatore), UNIQUE(id_giocatore), INDEX(id_giocatore));
Compito a casa: scaricate il manuale mysql (da http://www.mysql.com/ ) e provate a decifrare quanto scritto sopra. Cosa sono quei numeri tra parentesi? E quali sono gli altri tipi di campo?
Che differenza passa tra un campo CHAR ed un VARCHAR? Non spaventatevi, dovrebbe essere anche divertente spulciare tra i vari tipi di campo. Mysql supporta almeno 26 tipi di campo diversi, quindi.. buon divertimento 🙂
Ovviamente, sono a vostra disposizione sul forum per i chiarimenti del caso.
Nella prossima lezione vedremo come inserire nuovi record in una tabella e modificare i campi.
Nulla vi vieta di visitare mysql.org e anticiparvi un po’ di lavoro. Vedremo anche qualche tool più semplice della riga di comando. Intanto digerite bene questi argomenti, visto che, con 24 kb di lezione, vi trovate di fronte alla dispensa più “corposa” (battuto il record di 20 kb delle lezioni 2 e 3).
Dimenticavo: dal prompt dei comandi digitate “quit” per uscire da mysql (che vi saluterà con un “bye”).