Introduzione alle statistiche web
Uno degli script più richiesti nel forum di web-link.it è un servizio di statistiche. Del resto chi di noi non vorrebbe sapere quante persone entrano nel proprio sito? Oppure conoscere che browser usano, o a che ora si collegano?
Avventuriamoci quindi, dopo il guestbook, e creiamo la nostra seconda applicazione: un servizio di statistiche che non abbia nulla da invidiare ai più blasonati della rete!
Tutto quello che ci occorre è un dabase mysql e, ovviamente, un server php. Se non avete un servizio di hosting a pagamento, potete usare per lo spazio web altervista.org e per il database freesql.org. L’applicazione non richiederà molte risorse, anche se ovviamente il peso della base dati crescerà ad ogni visita degli utenti.
Se avete seguito le lezioni sul guestbook, non troverete difficoltà nella creazione di questo script. Del resto sarà PHP ad occuparsi di rendere disponibili informazioni quali il tipo di browser usato, l’ora di collegamento o l’indirizzo IP dell’utente.
Il difficile viene invece dal funzionamento del protocollo HTTP. Come saprete, quando ci colleghiamo ad internet siamo identificati nella connessione da un numero di 4 terzette di cifre (come 241.122.114.111, ad esempio). Questo numero è il famoso “indirizzo IP” ed è l’identificativo univoco di una connessione. Il numero viene stabilito dal nostro provider.
Per alcune connessioni, come quelle ADSL business, il numero di connessione è sempre lo stesso (più o meno come fosse un numero di telefono). Per altri servizi, come quelli gratuiti o Alice Adsl per uso abitazione, il numero cambia ad ogni nuova connessione.
Questo significa che Diego Maradona si può collegare con Alice, avere un indirizzo IP, e dopo aver controllato la posta disconnettersi. Dopo 5 minuti può arrivare Antonio Careca, altro cliente Alice ADSL (ovviamente i nomi sono di “fantasia”) e vedersi assegnato dal provider lo stesso numero di Diego. A proposito, domenica il Napoli Soccer ha riassegnato la maglia numero 10 di Maradona, che invece era stata ritirata. Che scempio! Chiusa parentesi.
Quando un utente dispone di un indirizzo IP fisso (IP sta per “Internet Protocol”, il discorso sarebbe interessante ma cosi vasto che è meglio non approfondire in questa sede) si dice che ha un indirizzo statico.
Quando invece gli utenti dispongono di indirizzi diversi ad ogni connessione (magari per pura coincidenza qualche volta possono anche essere riassegnati alla stessa persona) si parla di IP dinamico.
Cosa c’entra questo discorso con il nostro servizio di statistiche? Purtroppo c’entra perché ci impedisce di fatto di avere un servizio che restituisca il numero di visitatori univoci del nostro sito.
Se esistessero solo indirizzi IP statici saremmo a posto: basterebbe estrarre dalla base dati tutti i visitatori distinti per indirizzi diversi e avremmo il totale degli ospiti. Questo discorso perde però di efficacia con gli indirizzi dinamici, visto che lo stesso indirizzo può significare diversi visitatori. Senza contare quei casi in cui utenti diversi si connettono con lo stesso indirizzo IP (Internet cafè, LAN aziendali ecc).
I servizi di statistiche professionali “risolvono” il problema considerando un tempo di timeout. Se un indirizzo IP si collega al nostro sito, e dopo mezz’ora lo rivediamo, vuol dire che si tratta di un nuovo utente. Difficilmente infatti un utente si collega ad un sito e ci ritorna a distanza di mezz’ora.
Si tratta di una soluzione approssimativa, io ad esempio mi collego con ADSL e torno sul forum di web-link proprio ogni mezz’oretta- ora per controllare nuovi messaggi. E finché non mi disconnetto, il mio indirizzo rimane sempre quello.
Altro esempio dell’approssimazione (forzata) di un servizio di statistiche per il web è quello di un portale creato da un’azienda ed impostato come prima pagina del browser dei clienti.
E’ una situazione che ho visto con i miei occhi. Quel portale riceve 20 visite al giorno, con costanza invidiabile, per poi avere una flessione (guardacaso) prossima allo zero nel mese di agosto.
Ecco allora che un servizio basato piu sul dato giornaliero/mensile che su quello degli indirizzi IP risulta efficiente e permette di capire che su quel sito in pratica non ci va più nessuno.
Iniziamo quindi la nostra applicazione tenendo però presente questa premessa e chiedendoci cosa vogliamo effettivamente.
Visto che il corso è destinato ad utenti alle prime armi e vuole consentire di creare qualcosa di utile e funzionale, lasciamo stare aspetti avanzati come il tempo di timeout.
Nulla vi vieta però di implementarlo per conto vostro, magari nel forum di web-link. I dati che immagazzineremo infatti sono adatti a qualsiasi statistica: sarà compito della query finale elaborarli, ma a livello di memorizzazione informazioni avrete a disposizione tutto il necessario per le vostre esigenze.
Decidiamo di memorizzare infatti, per ciascuna pagina:
- il nome del file;
- la data e l’ora di connessione;
- il browser utilizzato dall’utente;
- il linguaggio del browser;
- l’indirizzo IP dell’utente;
- la pagina di provenienza.
Niente male vero? Una mole di informazioni che difficilmente un servizio di statistiche gratuito vi mette a disposizione.
Tra l’altro, creandolo attraverso questa lezione, avrete bene in mente il processo dello script e potrete quindi modificarlo graficamente come vorrete.
Progettiamo la base dati
Come possiamo risalire alle informazioni che vogliamo memorizzare? Ho già parlato troppo nella premessa per cui ora vi propongo un bello schema con le informazioni, il modo di recuperarle in PHP ed alcune note a corredo. Cosi, se vi dovessero servire per altri script in futuro, potrete ricorrere a questo schemino.
| Informazione | Come ottenerla | Note |
| Nome della pagina | Con la variabile $_SERVER[‘REQUEST_URI’] oppure con $_SERVER[‘SCRIPT_NAME’] | $_SERVER[‘REQUEST_URI’] tiene conto di eventuali parametri passati dalla url (esempio pagina.php?var1=ciao), script_name memorizza solo il nome della pagina. |
| Data ed ora di connessione | Direttamente da Mysql con la funzione now() | Usare la funzione date_format() di Mysql per estrarre poi i dati nel formato voluto |
| Browser | $_SERVER[‘HTTP_USER_AGENT’] | Restituisce anche informazioni sul sistema operativo (esempio ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90; dial)’) |
| Linguaggio | $_SERVER[‘HTTP_ACCEPT_LANGUAGE’] | – |
| Indirizzo IP | $_SERVER[‘REMOTE_ADDR’] | – |
| Pagina di provenienza | $_SERVER[‘HTTP_REFERER’] | Non sempre è possibile disporre di questo parametro (ad esempio non è possibile quando si digita a mano l’url nel browser o si accede via javascript) |
Tutto abbastanza chiaro vero? Se avete qualche dubbio sulla differenza tra le variabili $_SERVER[‘request_uri’] e $_SERVER[‘script_name’], guardate questo esempio:
pagina.php?var1=ciao&var2=mondo: con $_SERVER[‘REQUEST_URI’] viene memorizzato pagina.php?var1=ciao&var2=mondo
pagina.php?var1=ciao&var2=mondo: con $_SERVER[‘SCRIPT_NAME’] viene memorizzato pagina.php
Decidete voi quale metodo usare. A volte i parametri sono influenti per il contenuto della pagina. Prendete OScommerce, il popolare sistema php per il commercio elettronico. Viene memorizzata nella url per ciascun utente, su tutte le pagine, una variabile di sessione per ricordare i dati di login ed identificare l’utente. Se usate un sistema del genere e ricorrete a $_SERVER[‘request_uri’], in fase di estrazione dati mysql vi ritroverete con pagine diverse anche quando sono uguali!
In un sistema di portali invece è corretto distinguere in base alla url:
partita.php?id_partita=34
può contenere foto e commenti su Napoli-Milan, partita con ID 34 nel db;
partita.php?id_partita=45
può riguardare Napoli-Juventus.
In un sistema del genere è corretto avere informazioni distinte in base ai parametri della url, e non solo in base al nome del file.
Scegliete la soluzione a voi più congeniale, per questa lezione useremo $_SERVER[‘request_uri’] ma va da sé che sarà lavoro di due minuti modificare lo script con $_SERVER[‘script_name’].
Creiamo la nostra base dati.

Apriamo mysqlControlCenter o phpMyAdmin e creiamo un nuovo database o usiamo quello del guestbook (almeno per questo esempio, poi ovviamente online userete quello che già avete) e sopratutto una nuova tabella.
Chiamiamo la tabella “statistiche” ed inseriamo i campi necessari per le nostre informazioni. Anche qui ricorriamo ad una tabella cosi da semplificare la lettura. Chiamiamo la tabella “statistiche” ed inseriamo i campi. Usiamo un campo ID per assegnare un indice ed una chiave univoca in modo da organizzare e velocizzare le ricerche:
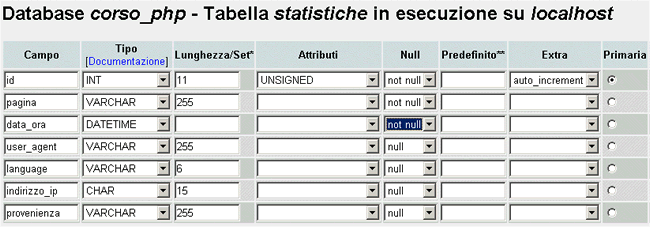
Visto che la guida è seguita anche da non vedenti, ripeto in una tabella quello che appare nell’immagine qui sopra, ovvero il nome e il tipo dei campi:
| nome del campo | Tipo | Lunghezza | Note |
| id | INT | 11 | unsigned, not null, autoincrement, primary |
| pagina | VARCHAR | 255 | not null |
| data_ora | DATETIME | not null | |
| user_agent | VARCHAR | 255 | null |
| language | VARCHAR | 6 | null |
| indirizzo_ip | CHAR | 15 | null |
| provenienza | VARCHAR | 255 | null |
Credo che tutto sia chiaro, del resto a parte il contatore e la data abbiamo tutti campi stringa. Per l’indirizzo IP usiamo tranquillamente un CHAR, quindi una stringa a lunghezza fissa, visto che tanto un indirizzo IP può oscillare poco (tra 11 e 15 caratteri).
Per gli altri va bene un varchar, il protocollo HTTP non consente url superiori ai 255 caratteri e va bene cosi. Infine ricordiamoci di consentire su alcuni valori il null, non sempre infatti saranno disponibili alcune informazioni come la provenienza e quindi meglio consentire campi vuoti.
Riempiamo il database
A questo punto è semplicissimo inserire i dati nella tabella. Ovviamente la query mysql va ripetuta su tutte le pagine (a meno che non vogliamo escludere di proposito qualcuna dalle statistiche), ed è intelligente usare un bell’header.inc.php da includere poi in tutto il sito.
L’istruzione sql è la seguente, anche qui tutto molto semplice. Occorre fare attenzione ai caratteri di escape sulle stringhe, nulla di più:
$basedati=mysql_select_db(“guestbook”)or die(mysql_error());
//statistiche
$sql=”INSERT INTO statistiche (pagina,data_ora,user_agent,language,indirizzo_ip,provenienza) values(‘” . $_SERVER[‘SCRIPT_NAME’] . “‘,now(),'” . $_SERVER[‘HTTP_USER_AGENT’] . “‘, ‘” . $_SERVER[‘HTTP_ACCEPT_LANGUAGE’] . “‘,'” . $_SERVER[‘REMOTE_ADDR’] . “‘,'” . $_SERVER[‘HTTP_REFERER’] . “‘)”;
@mysql_query($sql) or die(mysql_error());
Come avrete visto abbiamo usato il carattere “@” davanti mysql_query. Questo per evitare che PHP restituisca a video dei messaggi in caso si verifichino errori nella query. P
uò capitare infatti che la query restituisca errori quando la pagina riceve connessioni “strane” come quelle degli spider dei motori di ricerca. Motori che andrebbero ad indicizzare le vostre pagine con un bel “warning: ecc.”.
Con il segno di chiocciola davanti una funzione, viene “spento” l’output e la stampa degli errori. Questo sistema funziona con tutte le funzioni php, anche se ovviamente ne va fatto un uso intelligente riservato a quei casi in cui si è sicuri che lo script non ha problemi.
Tutto qui. Adesso, ad ogni pagina, la tabella si riempirà con i dati degli utenti: difficile che un servizio di statistiche tra quelli in circolazione vi offra tante informazioni!
C’è però un problema: questo script memorizza anche le nostre visite. Questo comportamento può non piacere, perché non si tratta di visitatori ma.. di noi stessi.
Si tratta di visite che “gonfiano” il bacino di utenza del nostro sito. Possiamo risolvere manualmente con un sistema molto semplice: passare dalla url una variabile durante le nostre connessioni.
Se lo script rileva nella url (quindi nell’array $_GET) questa variabile, non considera la visita.
Correggiamo lo script in questo modo:
$sql=”INSERT INTO statistiche (pagina,data_ora,user_agent,language,indirizzo_ip,provenienza) values(‘” . $_SERVER[‘SCRIPT_NAME’] . “‘,now(),'” . $_SERVER[‘HTTP_USER_AGENT’] . “‘, ‘” . $_SERVER[‘HTTP_ACCEPT_LANGUAGE’] . “‘,'” . $_SERVER[‘REMOTE_ADDR’] . “‘,'” . $_SERVER[‘HTTP_REFERER’] . “‘)”;
@mysql_query($sql) or die(mysql_error());
}
Se richiamiamo la pagina in questo modo:
pagina.php?noStat
bypassiamo il servizio di statistiche e la visita non viene contata.
Si tratta di un sistema molto artigianale, sia perché dobbiamo scrivere “a manina” ogni volta nella url il parametro, sia perché anche gli utenti esterni potrebbero, una volta conosciuto il nome della variabile, scriverla sulla url e non risultare nel servizio di statistiche.
Verificate voi se ne vale la pena. Potete al limite creare la variabile con un nome diverso da “noStat”, magari “fgi30h43jhsoi”. Certo poi diventa un’impresa scriverla ogni volta nel browser.
Estraiamo le statistiche
Adesso viene il difficile: estrarre i dati. Per fortuna mysql ci viene incontro con delle funzioni matematiche davvero utili:
count(*) restituisce il totale dei record di una tabella.
Possiamo combinare count(*) con una clausola WHERE per ottenere il totale di tutti i record che soddisfino una determinata condizione.
Esempio1: vogliamo estrarre il totale di tutte le visite odierne.
Nel db abbiamo memorizzata l’informazione relativa alla data, tuttavia se utilizzassimo questa sintassi:
SELECT COUNT(*) FROM statistiche WHERE data_ora = now()
ci troveremmo con 0 o pochissimi record, visto che now() cercherebbe la data nel formato giorno/mese/anno/ore/minuti/secondi.
A noi serve invece di trovare tutti i record della data nel formato giorno/mese/anno senza contare i minuti/secondi.
Per raggiungere questo scopo possiamo usare un’altra funzione di mysql, date_format, che formatta una data:
select * from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’)
Visto il meccanismo? Formattiamo allo stesso modo la data del db e quella di oggi, escludendo i minuti e i secondi che ovviamente andrebbero a falsare il risultato.
Eseguiamo la query nel solito modo e, grazie alla funzione mysql_result (usiamo questa perché tanto abbiamo un solo risultato, il totale delle pagine) vediamo quante pagine del nostro sito sono state visitate oggi:
$sql=”select * from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’)”;
$result=mysql_query($sql) or die(mysql_error());
$totale_visite_oggi=mysql_result($result,0,0);
?>
Per sapere quali pagine sono state visitate, basta estrarne i nomi, sostituendo a count(*) il nome del campo che conserva le pagine:
$sql=”select pagina from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’)”;
$result=mysql_query($sql) or die(mysql_error());
while($row_pagine=mysql_fetch_array($result)){
echo $row_pagine[‘pagina’] . “<BR>”;
}
?>
A questo punto potete avere l’elenco dei browser o degli indirizzi IP allo stesso modo.
Lo script qui sopra però stampa a video le varie pagine (o i browser, quello che volete visualizzare) una volta per ogni visita, per cui potremmo avere anche centinaia di record con lo stesso risultato.
Mysql ci viene incontro con la parola chiave DISTINCT, che permette di estrarre ogni valore una volta sola. Se, ad esempio, 4 utenti visitano la pagina “corso.php”, l’esempio precedente la stampa 4 volte; l’esempio che vedete qui sotto la stampa una volta sola:
$sql=”select distinct pagina from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’)”;
$result=mysql_query($sql) or die(mysql_error());
while($row_pagine=mysql_fetch_array($result)){
echo $row_pagine[‘pagina’] . “<BR>”;
}
?>
Abbiamo visto come sapere quante visite abbiamo ottenuto in un determinato periodo di tempo; abbiamo visto come sapere quali pagine sono state visitate. Manca la parte migliore: sapere quante volte ciascuna pagina è stata visitata!
Scopriamo una nuova funzione di mysql (niente male come db, vero?): group by. Più che una funzione, viene chiamata “clausola”. Permette infatti di restringere, ordinare il risultato in base ad un Gruppo.
Guardate l’esempio, è più facile a farsi che a dirsi:
$sql=”select pagina, count(*) from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’) group by pagina”; $result=mysql_query($sql) or die(mysql_error());
?>
Questa query restituisce due colonne, pagina e count(*), uno con il nome del file e l’altro con il totale delle visite ottenute!
Infatti dicendo “group by pagina” abbiamo dato istruzione al db di raccogliere ci� che ha estratto con count(*) e sommarlo per ciascuna pagina (ecco il concetto di “raggruppamento”).
Attenzione però: il campo count(*) non può essere richiamato nel ciclo while (che infatti sopra abbiamo omesso) perché non ha un nome. Viene estratto dalla query, ma non ha un nome con cui possiamo utilizzarlo, come abbiamo fatto finora con $row_pagine[‘pagina’].
Nessun problema: mysql ci consente di assegnare un nome al risultato di una funzione, un cosidetto “alias”.
Modifichiamo la query con la sintassi seguente (notate “as totale”):
$sql=”select pagina, count(*) as totale from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’) group by pagina”;
$result=mysql_query($sql) or die(mysql_error());
while($row_pagine=mysql_fetch_array($result)){
echo “Pagina: ” . $row_pagine[‘pagina’] .” – Visite: ” . $row_pagine[‘totale’] . “<BR>”;
}
?>
Nulla vi vieta di modificare la query per ordinare i risultati in modo da stampare prima le pagine più visitate:
select pagina, count(*) as totale from statistiche where date_format(data_ora,’%d-%m-%Y’)=date_format(now(),’%d-%m-%Y’) group by pagina order by totale desc
Compitini a casa
A questo punto abbiamo uno strumento di statistiche davvero interessante. Vi lascio con dei compitini, visto che con ottobre ricominciano a pieno regime le scuole.. 🙂
1) Estrarre il totale delle visite del sito, senza distinzione di giorno;
2) Estrarre il totale delle visite del mese corrente;
3) Estrarre il totale delle visite del ../.. (scegliete voi un giorno, basta che non sia quello odierno ma uno passato);
4) Estrarre una bella tabella html con 12 righe e 31 colonne e con tutte le visite del vostro sito, giorno per giorno;
5) Estrarre l’elenco degli indirizzi IP univoci. Si intende IP univoco anche quando lo stesso indirizzo non passa per il sito da piu di mezz’ora.
Ad esempio, l’indirizzo 223.123.123.56
e l’indirizzo
222.34.111.34
sono da considerarsi due indirizzi diversi, e fin qui tutto ok.
Se però l’indirizzo 222.34.111.34 visita la pagina “corso.php” alle 18:20: di oggi, e da li in poi non visita nessun’altra pagina del sito (nemmeno la stessa corso.php) e.. alle 18:51 si presenta di nuovo l’indirizzo 222.34.111.34 e visita una qualsiasi pagina.. va considerata come doppia visita perché probabilmente in questa mezz’ora lui si è disconnesso ed il provider ha assegnato l’indirizzo IP ad un altro utente.
I primi 2 esercizi sono alla portata di tutti, il 3 è un livello più difficile, il 4 siete davvero bravi, il 5.. scrivete voi la prossima lezione 🙂